Centering and scaling
Centering
Centering makes the center of each variable (column of the dataset) equal to zero, hence moving the center of the data cloud in the variable space to the origin. Usually, the center of values is estimated by computing their arithmetical mean (average) but in some cases the median can be used instead. Mathematically, it is done by subtracting mean/median from the data values separately for every column/variable.
In mdatools the centering can be done by using method prep.center(). The code chunk below shows how to apply centering to People data using both mean and median as the statistics.
library(mdatools)
# load People data
data(people)
# remove several columns which are very different from the others
data0 = people[, -c(6, 7, 8, 9, 11)]
# mean centering
data1 = prep.center(data0)
# median centering
data2 = prep.center(data0, type = "median")
# show boxplots
par(mfrow = c(1, 3))
boxplot(data0, main = "Original")
abline(h = 0, lty = 2, col = "red")
boxplot(data1, main = "Mean centered")
abline(h = 0, lty = 2, col = "red")
boxplot(data2, main = "Median centered")
abline(h = 0, lty = 2, col = "red")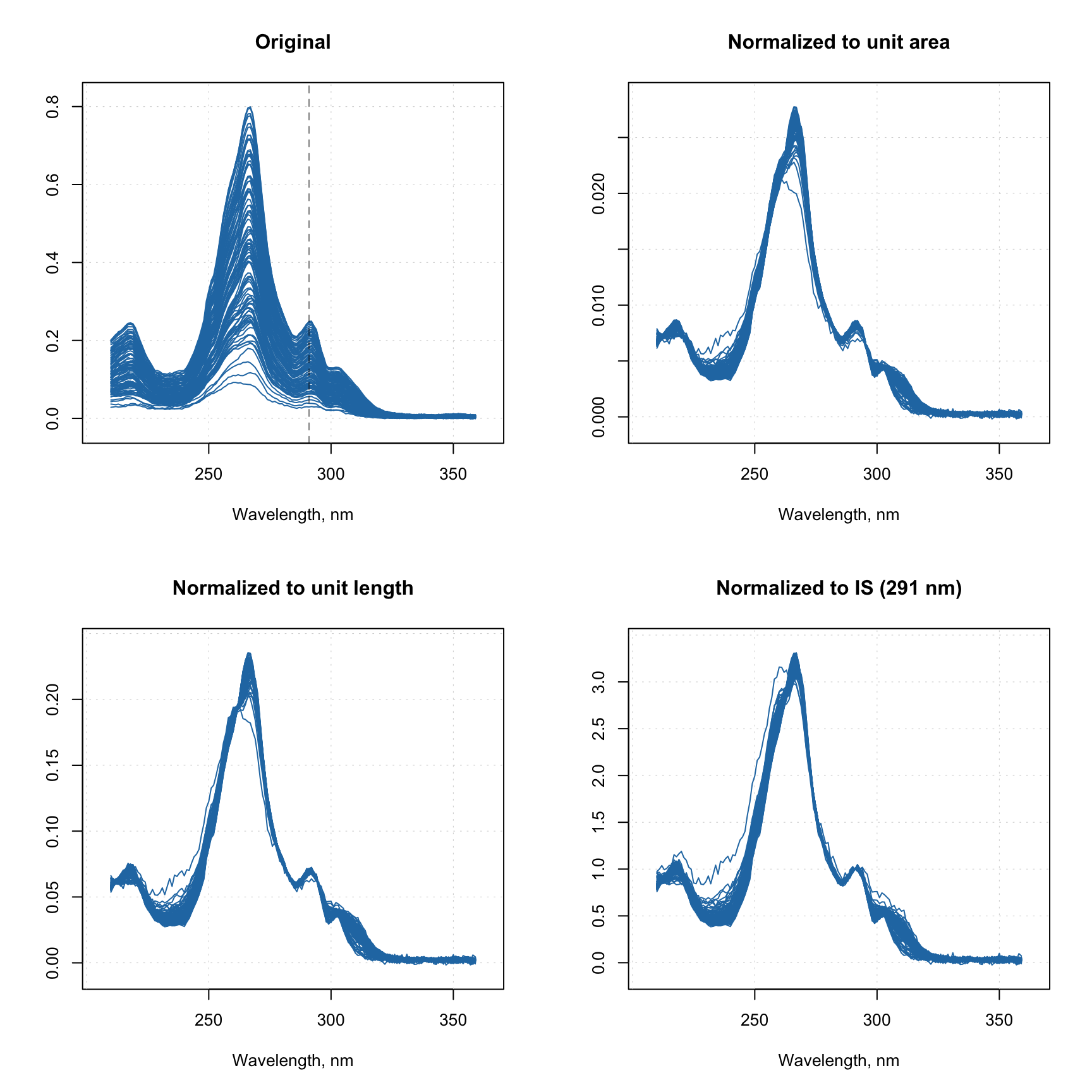
Scaling
Scaling is used to unify the spread of the data values. It is done by dividing the data values from each variable by a statistic representing the spread. The most common choice is to use standard deviation as a scaler, in this case scaling is also called standardization, it results in variables having standard deviation equal to one (unit). Alternatively, you can also use inter-quartile range (IQR = Q3 - Q1), the full range (max - min), or Pareto scaling when variables are divided by the square root of the standard deviation.
The code below shows how to implement them all (it assumes that you ran the previous code block already and People data is in the current R environment). Please pay attention that the People data is mean centered beforehand, otherwise it will be difficult to see the difference on the plots:
# mean center the data for better visualization
data0 = prep.center(people)
# standardization (default option)
data1 = prep.scale(data0)
# IQR scaling
data2 = prep.scale(data0, type = "iqr")
# range scaling
data3 = prep.scale(data0, type = "range")
# Pareto scaling
data4 = prep.scale(data0, type = "pareto")
# show boxplots for each case
par(mfrow = c(2, 2))
boxplot(data1, main = "Standardization")
boxplot(data2, main = "IQR scaled")
boxplot(data3, main = "Range scaled")
boxplot(data4, main = "Pareto scaled")
The prep.scale() method has also an additional parameter max.cov, which helps to avoid scaling of variables with zero or very low variation. The parameter defines a limit for the coefficient of variation in percent sd(x) / m(x) * 100 and the method will not scale variables with coefficient of variation below this limit. Default value for the parameter is 0 which will prevent scaling of constant variables (which leads to Inf or NA values).